4.5 损失函数(Loss Function)
损失函数(Loss Function) 是用来,评估当前通过模型得到的预测值和实际样本真实值之间差异的大小。通过损失函数的导数,可以得到当前迭代预测值趋近实际值的变化情况,即梯度。因此常被我们用来作为下一次迭代的依据。损失函数的计算涉及所有引入的参数,计算的尺度是从整个模型层面进行的。
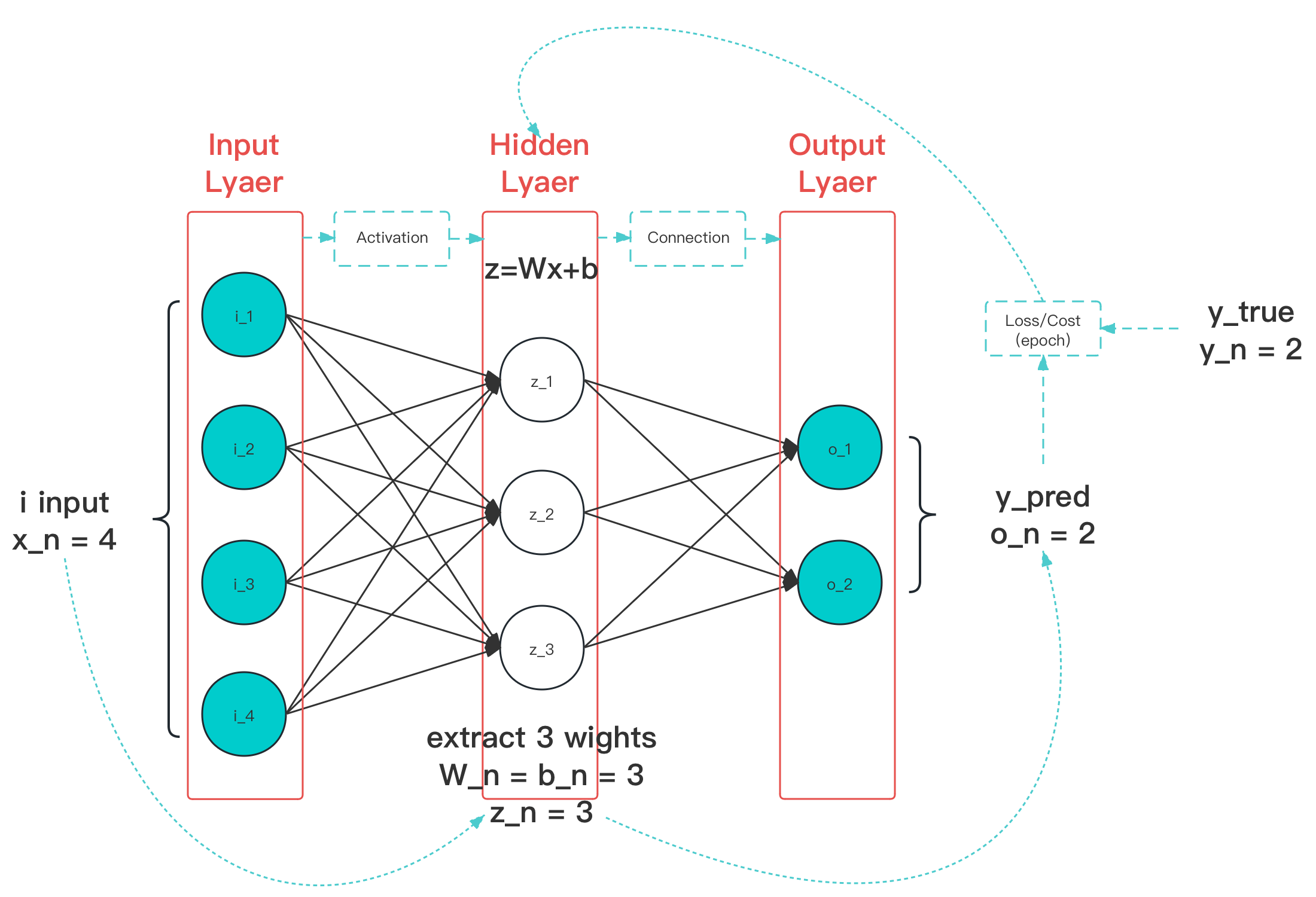
图 4-23 损失函数作用阶段(图中蓝色线条)示意图
如图,一次有效的损失函数计算,通常都是发生在一次全样本遍历(epoch)之后。我们通常使用的损失函数(Loss Function),严格意义上应该被称为 成本函数(Cost Function),即一种针对 整个训练集误差进行衡量 的目标函数。
损失函数的组成
损失函数的风险来源主要有两个:来自数据的风险 和 来自结构结构。这两种风险都会导致训练模型容易过拟合,而使得泛化能力受到影响。我们可以通过降低模型的复杂度来防止过拟合,这种方法被称为 正则化(Regularization)。
以最小化损失为目标,称为 经验风险最小化 :
以最小化损失和复杂度为目标,称为 结构风险最小化 :
我们通常用结构风险最小化的目标函数,作为实际损失函数。其成分广义上分为两个部分,损失项 和 正则项(在线上学习的角度上,还会引入第三项中心值项,用来约束新的迭代结果与历史记录差异性)。
损失项(Losses),用于衡量模型与数据的 拟合度(fitness) 的损失函数组成部分,也是实际需要进行选择性设计和采用的模型关键成分。这种针对性的处理,在聚类分析和人脸识别领域非常常见。根据功能的不同,又可以细分为 回归项(Regression) 和 分类项(Classification)。
正则项(Regularities),用于衡量模型 复杂度(complexity) 的损失函数组成部分。衡量模型复杂度的方法有很多。大部分是从权重对整个模型影响的层面来判断的,即从权重的大小,来衡量某个参数对整体模型的影响。
接下来,我们就分别从 回归项(Regression)、分类项(Classification)、正则项(Regularities)三种类型,来了解损失函数的使用。